Jekyll2024-08-04T03:52:44+00:00https://blog.vinaybhaip.com/feed.xmlRefinedA deepdive into the thoughts of a young computer scientist.Lessons from a Year Abroad2024-08-03T00:00:00+00:002024-08-03T00:00:00+00:00https://blog.vinaybhaip.com/2024/08/03/lessons-from-abroadOver the past year, I completed my Masters in Math at Oxford, traveling through the world along the way. It was an incredibly rewarding experience that led to a lot of personal growth, and I wanted to capture some of the biggest lessons I took away.
Why did I do a Masters at Oxford?
When I was doing my undergrad at UVA, I knew I’d be graduating a year early. The plan had always been to stay for an extra year for my Masters. I cared about doing a Masters because I wanted the traditional four year college experience.
In my final year at UVA, a professor gave a lecture about how he left his undergrad to study in South Africa for a year and how it was the best decision he made in his life – getting out of his comfort zone and turning off autopilot. This talk really struck a chord with me and made me look into programs outside of UVA.
I settled on doing my Masters of Math in Oxford for a couple of reasons:
It would be a completely different experience in a new country.
It was in math, something I always enjoyed academically, but wanted to strengthen. I realistically would never get the chance to do math in an academic setting in the near future, so spending a year purely on it excited me.
I would get to travel a lot.
It was only a one year program, so it fit into my timeline for starting fulltime work at the same time as my friends.
Lessons I’ve Learned
Getting Out of My Comfort Zone
When I got off the plane in the UK for the first time, I was excited for a new adventure, but I would be lying if I said I wasn’t terrified. The idea of just being in another country without anyone I knew was deeply uncomfortable, but as all things in life, the only way was forward. Even in a country where I originally knew no one, I made close friends from across the globe. Figuring out visas, bank accounts, phone numbers, etc. was hard, but it all worked out – it made me appreciate what immigrants go through even more.
In my time abroad, I got to visit over ten countries. In the past, I never had to book my own flights, figure out where to stay, and create a daily schedule all by and for myself. At first it was scary, but after that initial hump, it turned out to be so much fun. I realized how different cultures and ways of living compared to the US. I loved what each country brought to the table: the food, the traditions, the people, but one big takeaway was how much I took all the privileges from living in the US for granted. The cultural aura that the US exuded on the rest of the world made me feel even more pride for my home.
On the academic side, Oxford math challenged me in many ways. While one of my majors at UVA was math, I never truly felt like a math person before - it was always as if math was only something on the side I was interested in.
In most European universities, students only take classes in their major; for example, math undergrads at Oxford only studied math, whereas in the US, I was taking breadth courses that interested me ranging from lectures on carbon neutrality to the history of hip-hop. While I’m glad to have had the US undergrad experience, in my masters classes, I could definitely feel the imposter syndrome creeping in, especially with the faster pace of lectures.
One big lesson I learned was that I’m more capable than I give myself credit for; once I sat down for a few hours and reasoned through the material, I would feel pretty solid. Everyone has different routines for learning; some friends of mine would spend the entire day in the library, but that wouldn’t work for me – I often needed time for my brain to relax. Trusting my own process and the way I learn best worked out pretty well and I ended up doing great on my exams.
Enjoying Solitude
My friends would often stay home during the breaks, but I wanted to travel, so I dived into the realm of solo-traveling. It was something a few of my friends back home had raved about, and I would always say, “Man, I wish I could do that.” This year that mentality changed.
I saw so many different cities in Europe while staying in hostels, and I realized how much I loved solo-traveling. It felt freeing – I could do whatever I wanted (it was usually bakery hopping and journaling). I think fondly about that time: having no responsibility and just living. I distinctly remember sipping hot chocolate along a river in Ghent, Belgium, thinking, “I know nobody in this country.” It didn’t scare me, it felt like an escape from the woes of every day life.
I love hanging out with friends, but having time to myself made me introspective and appreciative for everything in my life. I hope to incorporate more time to do that, even when I’m not roaming the streets of Europe.
Staying Closer to Home
Everybody talks about how you make amazing friends abroad, and I did, but the ones back home got me through the year. This year, I put an effort to stay close with people who I cared about – it was something I told myself I’d do when studying abroad, and I’m glad I stuck with it (see my project Sealed). I’ve realized the results of compounding investments into relationships; I feel like I’ve gotten closer to friends back home by calling them every two weeks or so, even without being there in person. Had I not put in the effort, I realistically could have lost touch. I’m reminded of one of my favorite quotes from How I Met Your Mother:
You will be shocked, kids, when you discover how easy it is in life to part ways with people forever. That’s why, when you find someone you want to keep around, you do something about it.
I never went home to the US in my year abroad; it might be the longest I’ll ever go without returning home. This was an intentional choice to force me to travel and explore where I was, and while I have no regrets, I think visiting home once might’ve been nice. It was tough at times, but honestly not as bad as I would’ve thought. That’s because I didn’t really feel like my friends from home left. I’m so grateful for them: the ones who visited me and the ones I could call whenever and debrief about life updates.
How to Cook
One of the best parts of being in a European city like Oxford was how walkable it is. The grocery store was a five minute walk from my room, which made cooking really convenient, unlike my undergrad where I would need a car (which I had to rely on my roommates for). Cooking was just like anything in life; the more time I spent on it, the better I got – I was so impressed with how good food could taste. I’d be up late at night watching videos on the Maillard reaction and experimenting the next day like a scientist. I learned so much about the value of getting a good sear and using spices and marinades.
Cooking also made me appreciate even more the food I was consuming. Instead of just eating food and thinking it tasted great, I now think about what individual flavors combine to make me feel this way – for example, what are the different sources of salt and how do the different textures in the dish contribute to the overall experience? I’ll definitely miss being able to cook so often and having ingredients so readily accessible.
Getting in Shape
While studying was important at Oxford, I prioritized going to the gym and eating healthy, which I admittedly was not the best at during my undergrad. The result was night and day; I could confidently say I was in the best shape of my life and hope to add to the momentum I built up. I realized that having a gym a two minute walk away was an incredible motivator for working out. I was able to complete the Murph (without the weight belt… that will change soon) and now want to keep it as a yearly tradition. Consistently going to the gym revealed how hard work compounds over time; previously, I kept switching my routines and questioning if I was heading in the right direction. What I didn’t realize is that the most important thing about your gym routine is sticking to it.
Going abroad meant missing so many events back home and the FOMO was real. But I wouldn’t change any of it for the growth I experienced and the person I became.
]]>Sealed: Custom Wax Seal NFC Tags2024-03-24T00:00:00+00:002024-03-24T00:00:00+00:00https://blog.vinaybhaip.com/2024/03/24/sealedtl;dr: I designed custom wax seals and embedded NFC tags underneath them. When you tap your phone to the seal, it pulls up a custom website that hosts pictures and videos from my time abroad (securely!).
Wax sealed envelopes ready to be shipped out!
There’s something magical about receiving a card; it’s a physical and eternal representation of the time and effort someone spent on you. When I left the US last year to complete my Masters in Math at Oxford, a lot of friends would say “don’t forget to send us a postcard!” I wanted to live up to that promise – with my own twist on it.
I was walking with a friend through the city and I found a stationery store that was selling wax seal kits. This was exactly what I needed: an excuse to avoid writing my dissertation. I fell in love with the idea, but I didn’t like how I would just buy a generic “V” stamp that anybody else in the world could have. I wanted to make it special; after a conversation with another friend, I embarked on a new side project – Sealed: Custom Wax Seal NFC Tags.
Part 1: Designing the Seal
Not only were the wax seal kits in the store generic, they were also a bit expensive (>$30!). I found a shop on Etsy that would make and ship my own custom seal to me for around $10, an absolute steal.
For my custom seal, I already had an existing logo from my website, but I wanted to add some flair. After tinkering, I settled on this design:
The logo I designed and used.
The background has three lions from my college’s (Oriel College, Oxford) crest. This is where the lore started getting better – what if whenever I sent letters, the wax seal would embed information about the event/where it’s from? So if I send a wax stamp while I’m in NYC, the stamp would have skyscrapers in the background instead. This way, it becomes a souvenir that people can collect. There’s another easter egg in this logo that I won’t put here, but reach out to me if you’re curious!
To make the wax seals pop, I bought metallic sharpies and golden mica dust. The mica dust ended up more in my lungs than on the seals, but the sharpies worked great. I put it all together and did some trial runs, and it looked amazing:
This seal came out picture-perfect! It took several tries to find the right balance for how much wax to melt.
The design I originally sent in for the stamp had an issue with the masking, which drives me crazy to look at now, but it’s one of those things you don’t notice until it’s pointed out to you (no, I won’t point it out). We’ll just say it adds ✨character✨.
Part 2: Integrating NFC Tags
My friends and I have always wanted to use NFC tags1 for an interactive photo album. Sadly, this is another side project that has yet to come to fruition, so I was worried that by ordering more tags, they would just collect dust in my closet again. Luckily, this wasn’t the case.
The big question: does melting wax over NFC tags melt them/impede functionality? Thankfully, no. Though, I think I bought poor quality tags because they were a little finnicky and take a few taps with your phone angled the right way for it to trigger.
The inside of a card. Each letter had two seals; one for the outside of the envelope and one for inside the card, which had the NFC tag. You can see that the wax seal juts out a little bit due to the thickness of the NFC tag.
I then linked the NFC tags to a website I made that hosted photos from my time abroad.
Part 3: Building a Secure Photo Tiling Website
Making the website turned out to be less straightforward than I thought it would be. There were a few constraints I had for the project:
Display my pictures as tiles with captions on certain pictures
Keep the website under my main domain and stick with Github Pages
Be secure without having my pictures being publicly available online. My pictures aren’t anything sensitive, but in the age of AI where bots scrape the web for training data, having at least some protection would make me feel better.
The first bullet point was easy, I found this package for tiling photos. I put some custom CSS and made it look nice.
The (blurred) website with custom pictures/videos and captions on certain tiles.
The problem was that the second and third bullet points were in contention. Hosting it on Github Pages meant it would be a static website, but then any images would be public (images would be sent to the user with a request to the page or the url to the image would be in the source code).
One option was to password protect my webpage, though I would have to make my website dynamic and have a server. Maybe I’m stubborn, but I don’t want to do this. It adds to the maintainability of the website, and I like how everything is already hosted on Github Pages.
Another option would be to use a custom Google Photos album or something alike. This still isn’t hosted on my website, but at least there’s not much to maintain. I don’t like this option either though; I had a particular vision for how the images and captions would be displayed, and if I wanted to customize it more in the future or put something else linked on the NFC tags, it’s more straightforward if I have the architecture on my own site.
After some research, I came across Staticrypt. This was so interesting – it uses AES-256 encryption for a static website; the password you enter is used as a key to decrypt an encrypted webpage that was stored on the site.2 Pretty cool!
The last issue was with images. I couldn’t host the images on Github Pages, because then they’d be served on the webpage and could be scraped – even if I used Staticrypt. Instead, I put the pictures in an S3 bucket and used the links, which would also be a part of the encrypted source code. This way, no images would be sent to the user until the website was decrypted and reloaded.
There were some other details like compressing the images and videos so the website didn’t have horrible lag. I also modified the Staticrypt code a bit to suit my needs (I won’t dive into that here, because, well, that kind-of defeats the purpose of security measures, right?). The end result is a decently secure website that people can access with a specific password – it’s not the state-of-the-art, but gets the job done.
I then wrote a bunch of letters on Oxford-themed greeting cards and trusted Royal Mail from there! I’m pretty happy with how this project turned out, and hopefully this is the start of a tradition of mailing letters 😁.
In case you’re unfamiliar with them, they’re cheap pieces of electronics in plastic that embed data that your phone can read from nearby. ↩
I took a cryptography class in high school and had to implement AES-256; while I’m pretty sure my code was neither correct nor secure back then, it’s cool how it’s become a full circle moment. ↩
An example of a Dissonant Trail. Hover over/tap the image to see how it was constructed. Keep in mind these GIFs are large (~20 MB) if you are on data.
Background
I’m currently taking a class on Stochastic Processes and thought it’d be cool to make some generative art using what I learned. I have some bigger ideas involving stochastic processes in the works, but in the meanwhile, I thought I’d share some art that I made with it.
Making Dissonant Trails
I considered an $n$ discrete state system and wanted to visualize the transitions between the states. Instead of showing the probabilities of the transitions between states, I put particles at the states and simulated multiple timesteps to determine each particle’s path. Visualizing the path gives the “trail” part of the visual. The “dissonant” part comes from the noise of particles colliding with each other.
To make this abstract idea concrete, I used D3 to simulate the particles, and used D3-Force to make the particles move between states.
I considered one particle and visualized its path in a system and I got this:
At first, it looks like a bunch of scribbling, but there’s actually some interesting things going on. For example, at the top, the path stayed in the same state but sort-of moved around, probably colliding with other particles. Next, I considered multiple particles’ paths in a system:
Looks like a box of crayons!
If you’re interested in how each path is constructed, here’s a video showing the particles over time:
At this point, I thought it was pretty cool and started messing with some of the stylistic elements, like the stroke properties and background:
I wanted to try visualizing even more paths and particles, but the rendering on the page was becoming super slow, so I had to cap it off at a point.
Ultimately, the uniqueness of a generative piece comes from a) the number of states b) the transition matrix c) sampling from the transition matrix and d) moving the states location over time.
Examples
A graphic with some of the dissonant trails
Check out the full code to make your own Dissonant Trails here.
]]>Perlin Planets2021-01-26T00:00:00+00:002021-01-26T00:00:00+00:00https://blog.vinaybhaip.com/2021/01/26/perlin-planetsAn example of a Perlin planet. Hover over/tap the image to see it in action. Keep in mind these GIFs are large if you are on data.
Background
I came across this cool blog post from Atul Vinayak on what they call “noise planets.” I recommend checking out the post, but basically they created generative art to replicate art from Tyler Hobbs. The way to generate this is to make flow fields using Perlin noise, which I found incredibly fascinating. The post was pretty popular on Hacker News, but I noticed one of the comments said it was more like noise circles, rather than noise spheres. I decided to fix that.
Making Perlin Planets
The first step was replicating the work from the aforementioned blog post. I won’t go into that here because the blog post already does a great job. The main changes I made were making the edges of the circle have less opacity and reducing the stroke width at the edges to give the illusion of depth.
My first attempt at a Perlin planet. Remember to click it to see the GIF and that it may take a few seconds to load.
Looks cool! It was a bit more like a planet, but it wasn’t great. If I really wanted to make it planet-esque, I’d have to take the Perlin noise and put it on an actual sphere.
To do this, I intuitively generated random points on the sphere shell by sampling $\phi \in [0, \pi)$ and $\theta \in [0, 2\pi)$ (foreshadow: my intuition was wrong). Then, I used 2D Perlin noise passing in the current location of the point defined by $\phi$ and $\theta$ to determine the next location.
The last thing to do was to rotate the $\phi$ and $\theta$ of each point to give the feeling of the sphere rotating on an axis.
This was the result when rotating $\phi$ throughout time.
Weird. There’s two issues: 1. everything looks like it’s getting sucked into the center and thrown out on repeat and 2. if you look carefully, the boundary at $\theta = 2\pi$ (or $0$) isn’t continuous.
The first issue is due to a conceptual flaw; if you imagine a ring of points around a sphere’s vertical axis, they all have the same $\phi$. What this means is that incrementing the $\phi$ value is going to make all the points on that ring go up and down the sphere together, which when seen through the top, looks like it’s getting sucked into a vortex.
To deal with this issue, I decided to shift to standard cartesian coordinates. To rotate the coordinates around an axis, I used Rodrigues’ rotation formula.
The second issue has partially to do with the continuity of the flow fields. The idea is that noise(0) and noise(2$\pi$) won’t have the same value. This is fixed by saying if $\theta > \pi$, then $\theta = 2\pi - \theta$, for the purposes of drawing the flow fields. This means that it’ll be continuous everywhere.
Perlin planet with the issues above fixed.
A lot better! There’s still one more thing that’s fishy. The points at the poles are much more dense than that of the equator. After a bit of research, it turns out that my sampling method of $\phi$ and $\theta$ was wrong! If we think about it, let’s say we have the circle where $\phi = \frac{\pi}{100}$ vs $\phi = \frac{\pi}{2}$. We’d then be sampling $\theta$ from each of these two circles to gives us some points, but we’d have the same number of points on each of the two circles, when the circle at $\phi = \frac{\pi}{100}$ obviously should have less points since it’s a smaller circle. The fix for this is to sample $x, y,$ and $z$ from a Gaussian distribution and normalize them.
The last issue was how long the rendering time for these drawings took. To generate 100 frames, it took roughly 5 minutes. I created a Python script using Selenium to automate the process, adding a query string to specify things like the colors and axis of rotation. To give an even cooler effect, I change the axis of rotation over time as well. The result were some pretty cool Perlin planets.
Examples
A graphic with some of the planets
Check out the full code to make your own Perlin planets and to see more examples here.
]]>2020 Favorites2021-01-13T00:00:00+00:002021-01-13T00:00:00+00:00https://blog.vinaybhaip.com/2021/01/13/2020-favoritesIt’s been a long year, but I’ve grown a lot through autobiographies to personal projects to philosophy papers. In an effort to consolidate some of my favorite things I’ve learned from this year, I put together this short list.
Books
Becoming, Michelle Obama
“For me, becoming isn’t about arriving somewhere or achieving a certain aim. I see it instead as forward motion, a means of evolving, a way to reach continuously toward a better self. The journey doesn’t end.”
Best book I’ve ever read. The audiobook with her narrating her own story adds even more depth.
When Breath Becomes Air, Paul Kalanithi
“You can’t ever reach perfection, but you can believe in an asymptote toward which you are ceaselessly striving.”
Technically read last year, but too good to not include. Kalanathi explores his duality as a surgeon and a patient in his exploration for meaning.
What the Eyes Don’t See, Mona Hanna-Attisha
“This is also a story about the deeper crises we are facing right now in our country: a breakdown in democracy; the disintegration of critical infrastructure dues to inequality and austerity; environmental injustice that disproportionately affects the poor and black; the abandonment of civic responsibility and our deep obligations as human beings to care and provide for one another.”
A personal perspective on the Flint Water Crisis that makes for a powerful narrative.
Educated, Tara Westover
Between the World and Me, Ta-Nehisi Coates
Other Reads
Computing Machinery and Intelligence, Alan Turing
A philosophical examination to answer the question whether machines can think.
]]>From the Sets Rises the Numbers: Constructing the Reals2020-11-22T00:00:00+00:002020-11-22T00:00:00+00:00https://blog.vinaybhaip.com/2020/11/22/sets-to-numbers
What are numbers? In the previous post, we looked at the foundation of set theory to give us a tool to understand this question. Make sure to read that post here, and then come back to this article! It’ll be worth it; I promise.
In this post, we’ll dive into the meat of the problem: how do we use sets to define numbers?
From Sets to Numbers
Before we embark on our ambitious task to construct the real numbers, let’s start with something a bit easier. We’ll start with our basic counting numbers, working our way to integers, rational numbers, and then the formiddable foe of the reals. Let’s break down this problem into a couple of levels:
$\mathbb{N}$, the natural numbers (0, 1, 2, …)
$\mathbb{Z}$, the integers (…, -2, -1, 0, 1, 2, …)
$\mathbb{Q}$, the rational numbers (fractions)
$\mathbb{R}$, the reals
Level 1: $\mathbb{N}$
The natural numbers are what we’d consider as basic counting numbers, starting at 0 and going till infinity. (Sidenote: some people believe that natural numbers start at 1, but we’ll start with 0). To beat this level, we need to have a unique representation for all of these numbers.
This seems hard at first; we have to have a unique way to define each number all the way till infinity! Also, we can’t have squirmy definitions, it should be clearly defined since we’re going through all this effort anyways.
Let’s start with the first natural number: $0$. $0$ symbolizes nothing, so it feels natural to assign it as $\emptyset$, or $\{\}$. This is valid from one of our ZFC axioms, saying that there exists an empty set.
Now we have a starting point, how do we construct the next number? Let us define the successor operation:
$$S(n) = n \cup \{ n \}$$
This successor function takes a set and returns a new set as above. Let’s do an example: What’s the successor of $\emptyset$?
Well, $S(\emptyset) = \{ \} \cup \{ \{ \} \}$. We’re taking the union of these two sets, so we want to create a set that contains all the elements in each of the two sets. The first set, $\{ \}$, contains no elements, so it won’t “contribute” anything. The second set contains $ \{ \}$, so the union of the two sets must contain it as well. Thus, we get $S(\emptyset) = \{ \{ \} \}$.
Let’s run the successor function again on this result. So we want to calculate $S(S(\emptyset))$.
That’s a lot of curly braces! Don’t let that distract from what we’re doing: establishing a recursive function that creates a new set from our previous result.
Here’s the cool part: you’ve just defined the natural numbers. We assigned $0$ as $\emptyset$, and then we can assign $1$ as $S(\emptyset)$, $2$ as $S(S(\emptyset))$, and so on.
At this point, I encourage you to try constructing $3$ and check your answer here: Answer: $3 = \{ \emptyset, \{ \emptyset \}, \{\emptyset, \{ \emptyset \} \} \}$
Now that we’ve gone through this effort, it’s worth reflecting on what we’ve done. We have defined the successor function to define $n+1$ by calculating $S(n)$. Why do we have to go through this relatively complex process as opposed to other ways to construct $\mathbb{N}$? Let’s look at two candidates for what we could’ve done.
Define $n$ to be the number of items in a set. This set doesn’t have to contain numbers, but just contain random objects. For example, $0 = \{ \}$, $1=\{ red \}$, $2 = \{red, blue\}$. We define a number to be the number of elements in the set.
Problems with this approach:
a. This is circular! How do we count the number of elements in a set without knowing what numbers are to begin with?
b. There isn’t a unique representation for each number. With this definition, $2 = \{red, blue\}$, but $2 = \{red, green\}$. For every natural number other than $0$, there are an infinite number of ways to represent each number.
Define a recursive function such that $n+1 = \{ n\}$. Here, we wrap the previous element in another set and define $0 = \emptyset$.
Problems with this approach:
Technically, this doesn’t seem to be a bad approach. It simplifies our construction of each number much more. But, there’s a reason we chose to define the natural numbers with the successor function, because it allows for us to understand operations like addition and subtraction much more easily.
There can be many ways to construct the natural numbers; there isn’t one right answer. But we’ll stick to this successor approach.
The last thing to examine is whether this successor approach is really valid. It checks out because we’re using only our axioms for the function: the union operation is defined and the empty set is defined.
Defining operations
When we talk about natural numbers, we understand what it means to add, multiply and exponentiate. It follows that it should make sense with our construction.
To this end, we can use something called Peano Arithemetic. To maintain the focus of the article, I won’t go into it here, but if you want to know how we define these important operations, I’d recommend checking out the Wikipedia page!
Level 2: $\mathbb{Z}$
For our next challenge, we need to construct the integers. This is like the natural numbers, but includes negative numbers as well.
Let’s think intuitively: how do we know what a negative number is? Well, if I take a number like 0 and subtract 7, then we get -7. But how do we formalize that?
If you recall in the last post, we defined what an ordered pair was. We can write the number -7 as the ordered pair (0, 7), such that 0 - 7 = -7. In this way, we’ve created a negative number using natural numbers (which is totally valid since we’ve defined the natural numbers above).
The problem is that this isn’t unique. If I write the ordered pair $(1,8)$, we get $1-8 = -7$ just like $0-7 = -7$. This shouldn’t be too much of a worry when we define what is known as an equivalence class. What this means, loosely, is that if I have ordered pairs $(a,b)$ and $(c,d)$ and $a-b = c-d$, then we consider these ordered pairs to exist in the same equivalence class, meaning we can treat them as the same object. If you’d like a more rigorous explanation, I encourage you to check out the Wikipedia page linked above.
We can always also construct the natural numbers this way as well. For example, $3 = (4,1)$. This approach lets us define a value for all the integers.
Level 3: $\mathbb{Q}$
Now, we want to construct the rationals, basically just fractions (more explicitly, a quotient between two integers, where the denominator is non-zero). Before you read ahead, I encourage you to think about how we constructed $\mathbb{Z}$ and see if you can come up with a construction for $\mathbb{Q}$.
Hopefully, you recognized we can use ordered pairs again. To represent $\frac{2}{5}$, we can write it as $(2,5)$. To represent $\frac{-17}{14}$, we can write it as $(-17, 14)$. Remember, we can use any of the integers at our disposal because we’ve devised a valid way to construct them.
With the issue that this is not unique if we have a representation like $(2,5)$ and $(4,10)$ representing the same numbers, we can again use the idea from equivalence classes. Two pairs $(a,b)$ and $(c,d)$ are considered to be in the same equivalence class if $\frac{a}{b} = \frac{c}{d}$. If this seems circular to you, we can rewrite it as $ad = bc$ to avoid any problems.
Level 4: $\mathbb{R}$
This is what we’ve been waiting for. This is a much harder problem than what we had above: how do we create an all encompassing definition for numbers like $\sqrt{2}$, $\pi$, and $\frac{-e^{17}}{9}$?
Now, we can’t just stick it in an ordered pair like we’ve done before, because we can’t capture all of the reals this way.
Luckily, our good friend Cauchy is here, with what is known as a Cauchy sequence. A Cauchy sequence is a sequence (order matters!) of rational numbers such that the sequence converges to some number. We say that this Cauchy sequence is a representation of the number it converges to.
What does convergence mean? Let’s say we have a sequence $\{a_1, a_2, a_3, …\}$. If I were to pick any small positive number $\epsilon$, I should be able to find an $M$ such that all $m > M$ satisfy the following property:
$$ | a_m - L | < \epsilon $$
where $L$ is the limit. More simply, what this says is that the sequence will get closer and closer to the limit value.
Let’s see a visual example of how this works.
n=15
Drag the text with $n$ above and see how the graph changes!
What we’re looking at is a sequence of numbers that converges to a limit, in this case $5$. Now, this visualization of the sequence we have above only goes to $n=30$, but we can have an infinite number of elements if we want. Another important idea to consider is that all of these items in the sequence are rational numbers, because we already know how to define them.
The visualization above also only shows the limit of some arbitrary sequence to $5$, but we already know we can define $5$. Let’s try this method with something we know is irrational: $\pi$. Now $\pi$ presents a problem: we can’t represent it as a rational number. We can approximate it with values like $\frac{22}{7}$, but it’ll never be $\pi$.
The way we defined a real number is as a sequence of converging rational numbers. How can we write a sequence for $\pi$? Well, let’s think of this intuitively. We approximate $\pi$ by writing it to a certain number of decimal places. What do I mean by this? $3$ is close to $\pi$, but $3.1$ is even closer, and then $3.14$ is even more closer. We can construct a sequence as the following: $\{3, 3.1, 3.14, 3.141, 3.1415, 3.14159, 3.141592, …\}$. With each item in the sequence, we “reveal” one more number in the decimal.
These decimal numbers can be represented as rational numbers (think about why this is the case!). This means we have our Cauchy sequence! Let’s look at a visualization for how this would look like.
n=50
A bit anticlimactic. But it looks like a sequence of points that basically approaches the value of $\pi$, which is what we wanted! And these are all rational numbers, so everything checks out.
Let’s try this method with something a bit more obscure: $\frac{\pi^2}{6}$, which is approximately $1.644934$. There’s no way we can write this as a rational, because $\pi$ itself is irrational. So our goal is to find a sequence of rational numbers that converges to this irrational number.
Let’s define a sequence such that each element $a_n = \sum_{x=1}^{n} \frac{1}{x^2}$. According to this definition, the sequence would look like this: $( \frac{1}{1}, \frac{1}{1} + \frac{1}{4}, \frac{1}{1} + \frac{1}{4} + \frac{1}{9}, …)$, more compactly written as $(1, \frac{5}{4}, \frac{49}{36}, …)$.
It’s clear that this satisfies our condition that each element is rational, but does this converge to $\frac{\pi^2}{6}$? Let’s look at our visualization.
n=50
It works! We can see that the sequence of rational numbers is converging on $\frac{\pi^2}{6}$. If this sequence kept going on forever, it would converge to this number. This particular sequence was derived from the Basel problem, if you want to look more into it.
We now have an intuitive grasp that it works, but what’s really going on? This post isn’t going to mathematically prove it for you (if you’re curious, you can read up here). The reason Cauchy sequences can work is because the rationals are dense. Let’s imagine a unit square, the graph with $x$ within $0$ and $1$ and with $y$ within $0$ and $1$. There are an infinite number of rational numbers in this area. If I were to “zoom in” on any area in this unit square, there would still be an infinite number of rational numbers (I encourage you to think why this is the case).
Now let’s go back to the sequence of rational numbers we have that converge to an irrational number. Because the rational numbers are dense, if I choose any rational number, there is always another rational number that is closer to the irrational number. This is the key reason why we can construct an infinite sequence of rational numbers that converge to an irrational number.
We now have a representation of $\mathbb{R}$! When we talk about an element in $\mathbb{R}$, such as $\sqrt{2}$, the underlying meaning of $\sqrt{2}$ is an infinite sequence of rational numbers that converges to $\sqrt{2}$. The last thing to keep in mind is that there can be multiple sequences that converge to $\sqrt{2}$. We can use the same logic that we did in the previous levels, considering sequences that converge to the same number as lying in the same equivalence class.
Now Cauchy sequences are not the only representations of $\mathbb{R}$; another popular method is something called a Dedekind cut, which uses a similar construction, but is a little bit different.
Conclusion
And with that, you now know how to construct numbers from purely sets!
Why does this matter? In math, we want to have precise and accurate definitions. Without stable definitions, complex topics become ardent debates about terminology rather than content.
What’s the takeaway? In elementary school, you learned about counting numbers, then fractions, and eventually about real numbers. But what are these numbers? This post showed one way that we can attach a definition to these numbers, more than just abstract understandings of them.
I hope this visual walk-through on constructing the real numbers was helpful. If you think I’ve earned it, I would appreciate subscribing below (I promise there won’t be any spam). If this two-part tutorial was helpful or if you have any feedback, reach out to me at contact at mywebsitename dot com.
]]>Everything is a Set: Constructing the Reals2020-11-15T00:00:00+00:002020-11-15T00:00:00+00:00https://blog.vinaybhaip.com/2020/11/15/everything-is-a-set
What does it mean when we say $\sqrt{2}$? Well, you may say, it’s when we have a number $x$ such that $x^2 = 2$. That may satisfy you, but it shouldn’t. The notion of this abstract $\sqrt{2}$ is weird in that we define it as the “opposite” of squaring two. What does $\sqrt{2}$ look like?
Let’s take a step back. What do we mean when we say $2$? I can already hear the arguments, “Vinay, it’s two. Come on. I have two eyes. I have two ears. It’s easy.” To this end, we have a more concrete idea of what $2$ looks like, but we still don’t know what it is. This may seem acceptable to you, but considering that math is built on numbers, it’s worthwhile to examine what we mean by numbers. Here, I will give a walkthrough on constructing the real numbers, $\mathbb{R}$, which comprises of numbers like: $0, 42, -7, \frac{9}{17},$ and $\sqrt{38.9}$ to list a few.
By the end of this series on constructing the real numbers, you’ll learn how to represent a real number using foundational mathematical objects.
What is a set?
Note, feel free to skip this section if you know what sets are.
Since we’re taking on the task of constructing the real numbers, we need some tool. In this case, we’ll be looking at set theory as the basis for understanding objects.
We will use sets. There’s only one thing that a set tells us: whether an object is in the set or not. That’s it.
What are the implications of this definition? Objects in sets are unique. Second, there is no order to a set. We only know whether an object is in a set or not, meaning it has no position.
Let’s look at an interactive example. Move the items on the right in and out of the circle to see how the set looks like.
$$A = \{\}$$
Let’s do a quick review before we move on.
Is $\{marshmallow, red, 📘\}$ a set? Yes. Sets can have whatever we want in them.
If I have $\{x, orange, laptop\}$, and I added the element “x” to it, what does the set look like? Nothing changes. Sets can’t have duplicates. As a sidenote, if you do find a set that is written to have repeating elements, then that set doesn’t make sense; think of it like a typo in a sentence.
Are $\{falcon, blue\}$ and $\{blue, falcon\}$ different? Nope. Don’t let the order of elements trick you, these two are the same sets.
We now have the basics of sets down! Now to get to the interesting stuff.
ZFC
Now that we know what a set is, we need to have some basic truths we can agree on. These are known as axioms. I can’t prove these to you, but think of them as definitions. This is the foundation for everything we will do.
The way we’ll do this is through Zermelo–Fraenkel set theory. There is so much to look at here, but we’ll stick to the most relevant aspects of the theory.
There exists a set. I think we can agree on this one. This just says that it is possible to construct a set that obeys the rules like above.
There exists an empty set. An empty set is one which has no elements. This should feel like a reasonable assumption. Note, this set is unique. There’s only one way to exclude every object, and that’s by not having any object in it. We denote this set as $\emptyset$, which is just some mathematical notation; nothing to fear.
We can create a set that contains all the elements of two sets. This is the union operation. It’s best to show this by example: $A=\{hi, blue\}$ and $B=\{green\}$. Then $A \cup B = \{hi, blue, green\}$.
There are other axioms in ZFC, but these are the bare necessity for what we need to do.
Ordered Pairs Using Sets
This will be helpful later, but let’s try to understand how we’d represent an ordered pair using sets. Why do we care about this? Well, it seems reasonable we’d want to represent an object $(a, b)$ to be different than $(b, a)$. Essentially, we want to construct an ordered pair using an unordered set.
How does this make sense?! How do we create order from no order? We can’t just throw them in a set because $\{a, b\}$ is the same as $\{b, a\}$.
The solution is to encode each item as a set itself that contains previous elements. Let’s look at an example to understand this.
We want to represent $(a,b)$ as a set. According to what I said above, we would write this as a set like $\{ \{a\}, \{a,b\} \}$. How does this fix our problem? Let’s try to represent $(b,a)$: we get $\{ \{b\}, \{b,a\} \}$. Both sets have the item $\{a,b\}$ in it, but the difference is the set with either only $a$ or only $b$.
Now something important to see here is that inside each set, we can indeed have another set, because it’s just another element.
This way of constructing ordered pairs is meant to provide you with a reason to believe that we can do so. If this concept feels weird, don’t stress. The main takeaway is that ordered pairs can exist from sets. This allows us to construct something called a sequence, a collection of objects where the objects are ordered. A sequence is an “extended” ordered pair: it can contain as many elements as we’d like and maintain an order.
Wrapping Up
This post should’ve given you a brief background on set theory, the goal of which is to construct mathematical objects from this one basic concept: a set. We talked about some of the basic ZFC axioms and introduced how we can construct an ordered collection from this unordered collection.
Now what? We have the foundation for constructing the reals. The next post will do a deepdive in constructing the real numbers, starting with your basic counting numbers like $0,1,2,$ and so forth. We’re going to construct these complicated objects solely from the information above. As a plus, it’ll use cool interactive graphs to explain the concepts!
If this interests you (which it should!), consider subscribing to get updates on when the next post drops. Until then, I encourage you to think about how you’d go about constructing numbers using only the information we’ve covered!
]]>Summer of Stories2020-10-24T00:00:00+00:002020-10-24T00:00:00+00:00https://blog.vinaybhaip.com/2020/10/24/summer-of-storiesMy summer started in March, when school basically finished. Grappled with what I’ve always desired, unlimited free time, I sought a productive outlet. In this post, I’ll outline some of the highlights of my summer.
I started my break with a goal to refine how I code with the Missing Semester MIT course. This course goes into workflow tools for coding, ranging from teaching Bash to explaining cryptography. It was through this course that I discovered my love for Vim. It no longer was this abstract editor of hackers; it was a way to “code” the way I code. And I can’t explain how much time I’ve saved using Vim. The only problem is the time I’ve saved using Vim, I spend to convince others to use Vim. But it doesn’t matter; I just feel like a superhero using Vim.
Back to the topic, from this course I also learned about Git. Now, I already knew how to use Git, but this course showed me the inner workings, going into the ideas of trees, blobs, and directed acyclic graphs. What this is to say is that I became better at Git, and it was valuable.
The next milestone of my summer was rebuilding my personal website, something I’m really proud about. A more in-depth explanation of how I did this can be found here. In short, I modernized the website. It had been about 2.5 years since I originally made my website, but my new design was vastly different from the original one. Looking back, it’s cool seeing just how much I’ve grown in a relatively short amount of time.
The highlight of my summer was by far making HelioHex: a highly-configurable, modular, music-syncing lighting system. I wrote a post which has a demo and a tutorial of how I made it here. I don’t think I could do it justice with a summary here, so I highly recommend checking it out.
The bulk of my summer was spent working with the Looger Lab along with the Turaga Lab to use machine learning to devise better calcium indicators of neural activity. I worked with some amazing people across disciplines from chemistry to neuroscience to computer science. My summer work was amazing; from devising and constructing models using TensorFlow to writing regression tests, I felt like a real machine learning engineer. The coolest part was applying all my newfound knowledge from the Missing Semester course in scripting and Git.
With roughly a week left before school started, my family encouraged me to enjoy my remaining time before the stress of school hits. The problem is that I find it hard to kick back for extended periods of time. Don’t get me wrong, I love to relax, but I enjoy myself more when I’m productive. So after taking a few days off, I spent the last half-week of summer vacation learning D3.js and creating a visualization of my Spotify listening patterns. What this project taught me is that I love D3.js. It’s a bit complicated to understand the basics, but now that I do, I feel the world at my fingertips. I want to visualize data because I have a drive to tell stories. And so a few days on what was supposed to be a side-project now feels like a legitimate career path. Funny how things work like that 🙂.
Outside of CS
Outside of refining my computer science skills, I learned how to draw better. I followed the DrawABox lessons, which at one point, comprised of drawing 200 boxes freehand. It took a lot of work, but definitely helped me understand constructions better. I took a step back once school started, but hopefully I can dive back in during winter break.
Also, I’ve spent some time enjoying nature through walks and runs. Often, my mind needs space to escape the confines of the blue glow from my laptop screen, and taking in the scenery outside can help. It amazes me just how helpful it is, but it’s hard to build this as a habit. It’ll be something I’ll be working on in the future.
Lastly, I’ve read some pretty great books. I’m saving them for a future post, so stay on the lookout! Most of the books I read were personal biographies, a genre that I resonate with. There’s something comforting in listening to human stories, listening to how people learn, grow, and make the world around them better.
To this end, I’m calling this summer the Summer of Stories. From making a scrollyteller of my Spotify listening patterns to listening to autobiographies to witnessing lives of people affected by the pandemic to telling my own narrative with this blog, this summer feels like it revolved around stories. I’ve learned that I love stories because they make me feel human. They make me feel like I can connect to the experiences of others.
In summer-ry (get the joke?), I’d say this summer was pretty productive. I’ve picked up some cool new computer science tools and learned from valuable experiences. The optimist in me finds this reassuring that even in a pandemic, I can grow as a person.
]]>Building a Scrollytelling Visualization2020-10-11T00:00:00+00:002020-10-11T00:00:00+00:00https://blog.vinaybhaip.com/2020/10/11/spotify-vis-introIn my last post, I built a visualization of my Spotify data. I used the data to create a scrollyteller, which presents a story as you scroll (if you check out the post, you’ll see what I mean). If you found this interesting and wanted to see how I made it, look no further! Please keep in mind this was my first scrollyteller, but hopefully you’ll find this to be insightful.
There’s two main parts to this project - the graphs and the formatting for the story.
D3 Visualizations
What’s D3? It stands for Data-Driven Documents. A lot of people think of it as a graphing library, but it’s more than that; it’s a manipulation of data at low-level. It might not seem like much at first, but after working with it for a little bit you start to understand what makes it special.
The best D3 tutorial I used was this one from Square. It walks you through the basics of using D3 and all in all was a great introduction.
Why D3 over other libraries? Why not just use Tableau or Excel? Once you look through some projects that used D3, you’ll want to learn it. Seriously, this library is amazing. There are other libraries that fulfill somewhat similar purposes, but D3 is by far the most popular.
Creating a Bar Chart
Let’s go through how I built a simple bar chart for the Spotify Visualization post. In that post, I took my Spotify data and mapped it to a barchart for how long I listened to each artist. I’ll walkthrough the code, but I won’t give the data because I think it’s best if you find some other dataset and try to build it yourself (this just means you have to do a little bit more work instead of copy pasting code, but you’ll learn more!).
First, let’s create a bar chart. In something like Excel, this takes a couple of clicks, but in D3, we have to build it from scratch. First, we need to create a “canvas,” if you will, that we can draw the bar chart on. We do this with Scalable Vector Graphics (SVGs).
You’ll notice here we’ve “chained” together several functions; we can do this because when we call each function, it returns an instance of the object itself. So here, we select the HTML element with the class ‘chart,’ add on an SVG element, and then adjust the width and height for our canvas.
Now that we have our canvas, the logical next step is axes. To do this, let’s create some scales to build off. (Note, I say “scales” not “axes” here!)
varscaleArtistY=d3.scaleBand().domain(data.map((d)=>d.artist)).range([margin.top,height-margin.bottom])varscaleAmountX=d3.scaleLinear().domain([0,d3.max(data,(d,i)=>d.total_time)]).range([margin.left,width-margin.right]).nice();//nice rounds off valuesvarscaleAmountColor=d3.scaleOrdinal(d3.quantize(d3.interpolateWarm,26))
What’s a scale? Well, think of it as a function from the raw data dimension to the visualization data. Scales are functions that take in raw data, like what year it is for example, and return a concrete dimension for the display, like a pixel location.
We have three dimensions here. The first, scaleArtistY, maps a Spotify artist to a y value. This is what the domain and the range functions are doing, defining the input and outputs. d3.scaleBand() allows us to take categorical variables (like the names of Spotify artists we’re using) to “bands” (read more about it here).
scaleAmountX is the quantifier for how long I’ve listened to each Spotify artist. It uses scaleLinear() because we’re mapping a continuous variable to another continuous range. scaleAmountColor is a way to make the graph look a little bit more aesthetically pleasing.
Next, we define our axes. Remember, this is different from our scales. Axes are the lines you see on your screen, scales are functions that map one value to another.
Now that we’ve defined our axes, we need to draw them.
//g stands for "group"svg.append('g').style("font-family",font).style("font-size","1vw").attr('class','y axis').attr("transform",`translate(${margin.left},0)`).call(yAxis);svg.append("g").style("font-family",font).style("font-size","1vw").attr('class','x axis').attr("transform",`translate(0,${height-margin.bottom})`).call(xAxis);
Great! The next step, you might think is to draw the content of the graphs. But before we get there, let’s define some helper variables. There’s an important concept called data binding in D3, but this walkthrough’s goal in brevity will omit this. Data binding is a very important process in D3, so I highly recommend doing some research on this on your own (the Square tutorial above helps out with this).
Here, we’ve added an transition to the rectangle width. We now have an animation for the bar graph; let’s check it out!
Notice I’ve added text elements to the graph, but it’s nothing too different from what I had done before.
Any plain old graph making software like Excel would not have given us all this flexibility. Yes, there’s some more organization to do beforehand, but it gives us the tools to do whatever we desire. This is because at the core, D3 is not a graphing library but a data manipulation library.
But D3 goes beyond just some fancy animations. There’s so much that can be done with it, and this is only the beginning.
Scrollytelling and more
If you notice on the Spotify Visualization post, the charts animate as you scroll down the page. On the left side, there’s some updating text that describes the visualization as it changes. This beautiful way of demonstrating charts is known as scrollytelling, an aptly chosen portmanteau.
The library I used for this was Scrollama, and there is some example code in the repository. A good guide on making these scrollytellers was this article from the Pudding.
This post does not nearly explain everything that I did when making my Spotify Visualization scrollyteller. If you want to see the full code for this, check it out here. Feel free to reach out if you’ve got any questions!
Hopefully, this post has given you a brief look into what making a scrollyteller entails by showing a simple example alongside with the resources that I’ve used. My personal D3 explorations are just getting started, so stay on the look out for more interesting posts!
]]>Visualized: My Spotify Listening Patterns2020-08-22T00:00:00+00:002020-08-22T00:00:00+00:00https://blog.vinaybhaip.com/2020/08/22/spotify-artist-viz
Please put your device in landscape mode.
Which artists do I listen to the most? How has my listening patterns changed over time? Scroll down to reveal the story!
I recently uncovered my Spotify data documenting every song I've listened to for the past two years. Let's dive in.
This figure displays the cumulative time I spent listening to each artist's music. The artists I listen to fall into three tiers.
At the top of the list (with nearly 50 hours each!) are Drake and J. Cole. Personally, my favorite artist is J. Cole and I listen to a lot of the mainstream Drake songs, so this makes sense. No surprises here.
Kanye, Maroon 5, and Post Malone round up tier 2 at about 25 hours a piece. I'm surprised with Post Malone's appearance here—I didn't realize I listened to him that much.
And the rest trail behind below the 20 hour marker (Juice WRLD and Kendrick are close though!). It's worth pointing out that one of these artists is actually a podcast—Hello Internet.
This information is interesting by itself, but this neglects my listening patterns over time. Let's look more into the time dimension.
This shows a cumulative plot of which artists I listened to over time. Hover over each line to see which artist it corresponds to!
Drake and J. Cole have a fairly consistent growth pattern.
Post Malone has a huge growth in late 2019. Why? Hollywood's Bleeding dropped at the start of September—makes perfect sense.
Juice WRLD has a prolific rise after he passes away. Really wish I had listened to his music earlier; turns out his music is 🔥.
Maroon 5 has an insane increase to 25 hours in the matter of a few months. This happened toward the middle of quarantine when I was vibing with Maroon 5 on repeat. The almost vertical line captures just how much I listened to Adam Levine.
And that's it! There's still more interesting information in the data I didn't look at. For example, I chose only to look at the top 25 artists that I've listened to, leaving rich information behind, but that's for another day. You can download your own Spotify history here.
 Wax sealed envelopes ready to be shipped out!
Wax sealed envelopes ready to be shipped out! This seal came out picture-perfect! It took several tries to find the right balance for how much wax to melt.
This seal came out picture-perfect! It took several tries to find the right balance for how much wax to melt. The inside of a card. Each letter had two seals; one for the outside of the envelope and one for inside the card, which had the NFC tag. You can see that the wax seal juts out a little bit due to the thickness of the NFC tag.
The inside of a card. Each letter had two seals; one for the outside of the envelope and one for inside the card, which had the NFC tag. You can see that the wax seal juts out a little bit due to the thickness of the NFC tag. The (blurred) website with custom pictures/videos and captions on certain tiles.
The (blurred) website with custom pictures/videos and captions on certain tiles.
 Looks like a box of crayons!
Looks like a box of crayons!

 A graphic with some of the dissonant trails
A graphic with some of the dissonant trails A graphic with some of the planets
A graphic with some of the planets As always, a relevant comic from
As always, a relevant comic from 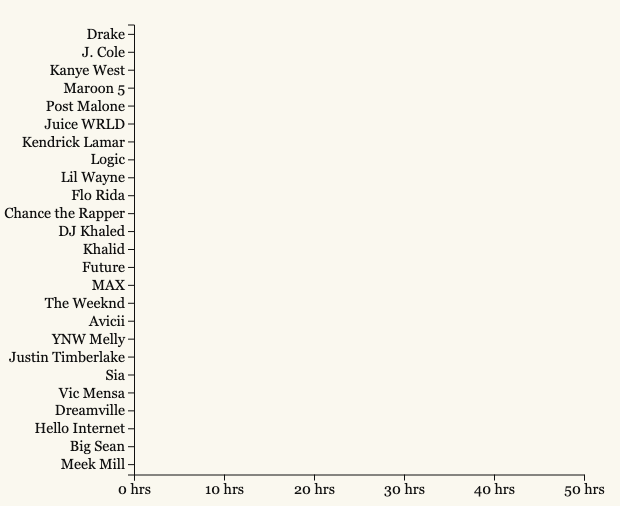
 Notice I’ve added text elements to the graph, but it’s nothing too different from what I had done before.
Notice I’ve added text elements to the graph, but it’s nothing too different from what I had done before.