Growth as Gradient Descent
Spending too much time thinking
Recently, I’ve been trying to be less of an overthinker. I constantly find myself getting bogged down by the weeds of planning—I have the illusion of making progress, but am I really changing anything?
A silly example of this happened when I was thinking about what body wash to buy. I spent at least thirty minutes researching brand qualities and the price trade-off (yes, my roommates did make fun of me). Was the body wash that was 10% more expensive worth the maybe 20% chance it had better ingredients? In my head, I justified this inner turmoil as, “this is a one time thing—once I figure this out, it’s solved and I never pay this time cost again.”
And this happens all the time at all scales: planning trips, picking food off menus, deciding what hobbies to do.
My mantra recently has been “execute” and I think executing more has helped me grow more into the person I want to be. As I thought about why executing more was important, I realized it reminded me of gradient descent 12.
Modeling thinking and executing as gradient descent
Imagine you’re in $n$-dimensional space, where every point represents the type of person you can be. Each dimension here is some trait/feeling e.g. how successful you are in your career, how healthy you are, how social you are. These are all abstract so substitute whatever you care here. Right now, you are a point in this space. Let’s denote this point as $x$ and the $n$-dimensional space as $V$ ($\approx\mathbb{R}^n$).
Every action you do moves you within this space—an action is a vector that you add to your current state. For example, maybe every food I eat is a small vector in some direction on the axis of my health. If I take a new job, that’s probably a big vector that’s in the direction of my career axis (maybe it also moves you in your social or health axis).
Additionally, for each point in this space, there’s some value that you ascribe to it (maybe this is how happy/satisfied you’ll be), which we can think of as any real number. Let’s call this value function $f : V \to \mathbb{R}$.
Naturally, you want to be the best person you want to be—this means maximizing this function. Let’s call this goal state $z = \arg\max f$.
The problem here is we don’t know what $z$ is, because we don’t know what $f$ is. You don’t know exactly how happy doing different things will make you, especially if they’re very different from what you do now.
How happy would you be if you quit your job and move across the world? We have a rough idea for what directions we want to step towards, but we can’t know how we’re going to feel as a certain version of ourselves until we actually experience it. We chave heuristics—getting more money and (for some) being more famous are probably good so we can want to take actions in those directions, but we don’t know for sure.
All we really know is $f(x)$, how happy we are right now. We probably have a rough idea for what $f(x+\epsilon)$ is, where $\epsilon$ is a small arbitrary vector. For example, you probably have an idea for how happy you’ll be if you go to work today. The way we try to maximize $f$ is by repeatedly taking steps in the direction that maximizes $f$, which is just gradient descent3.
What do your steps look like?
There are a few properties that come to play then from gradient descent:
- Size: How big are the steps you’re taking? 4
- Frequency: How many steps are you taking?
- Accuracy: How aligned are the steps you are taking in the direction of your goal?
All of these questions are important for how you’re growing as a person. I think I have a bias towards small steps—I view this as being risk-averse. The problem with being risk-averse is that you never really explore the global space. On the other hand, if you’re risk-taking and you take big steps all the time, you risk missing out on local optimizations and finding something you really love.
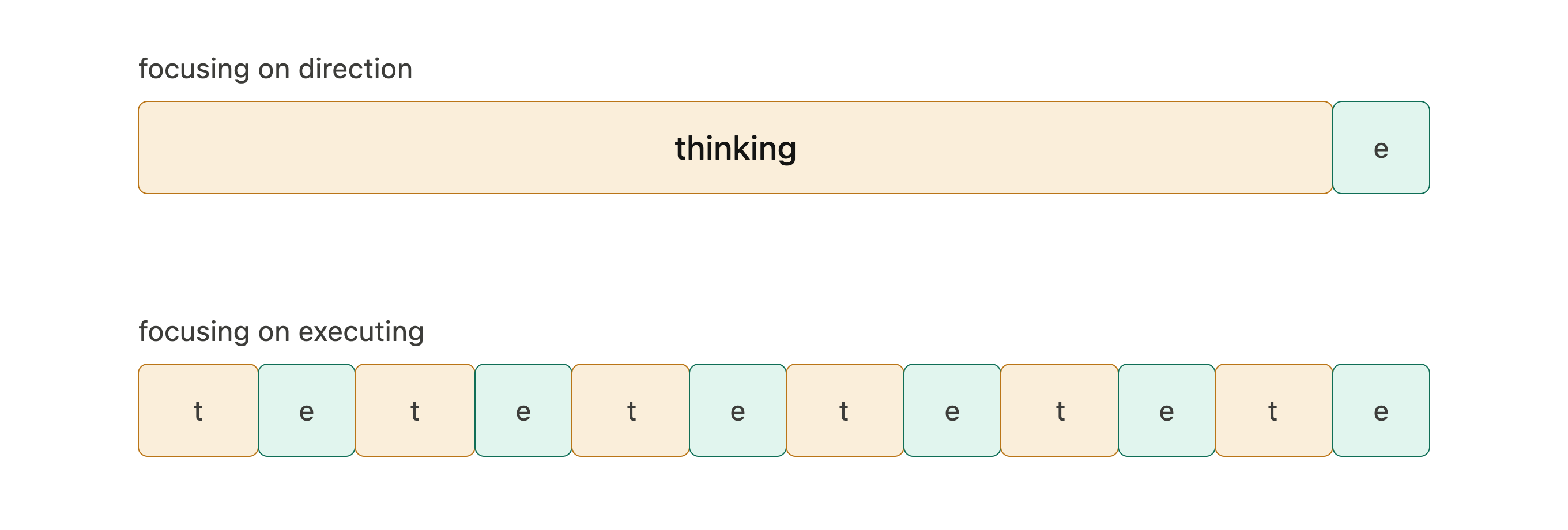
I think that the frequency and the accuracy of your steps are intertwined. Spending time to make sure your steps are accurate comes at the cost of having less time to make more steps.
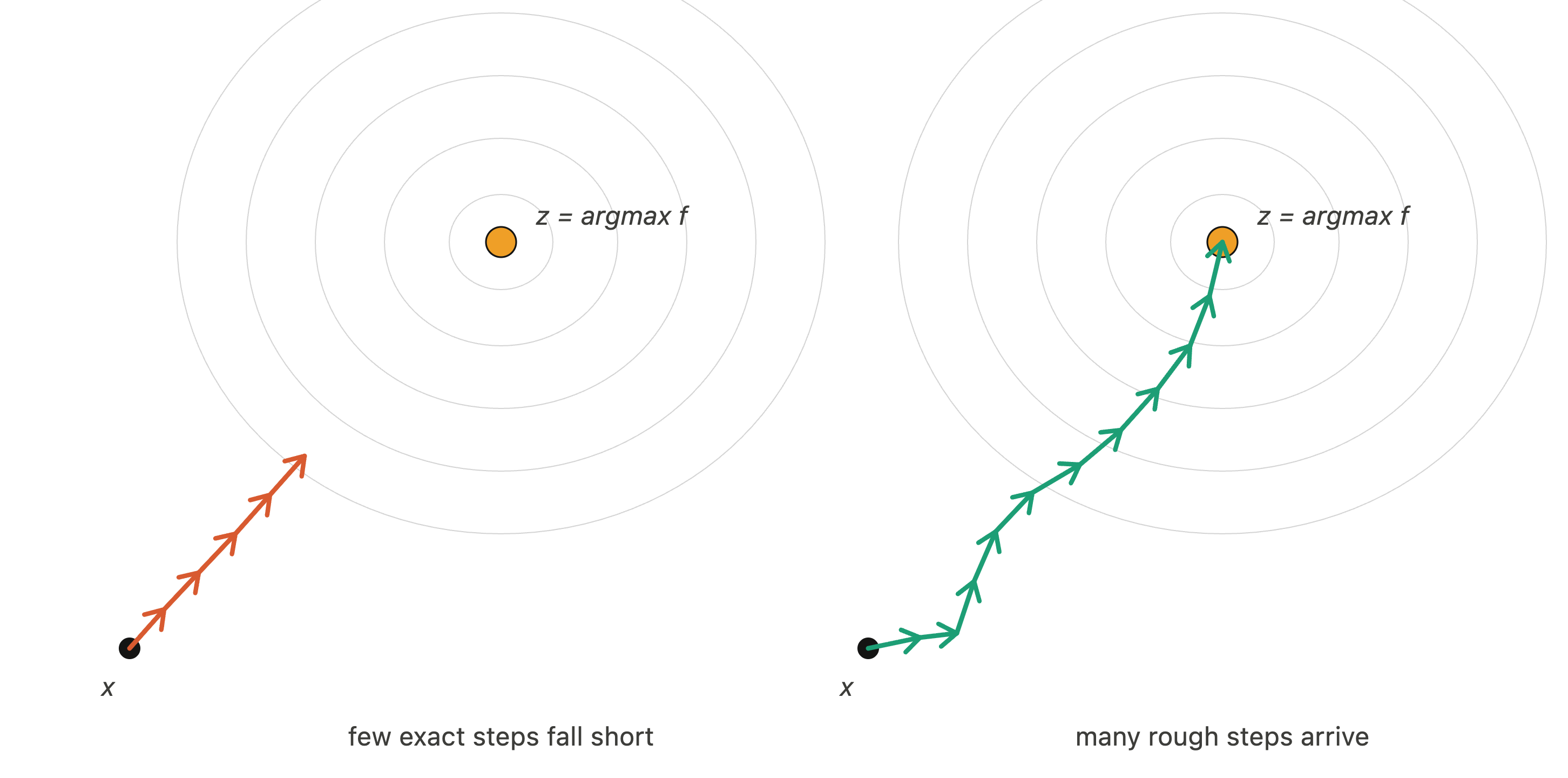
Taking less accurate steps might also be good on their own merit. Sometimes being less accurate lands you somewhere unexpected that you like even better. One parallel I noticed was when I was traveling in Vienna recently. I wanted to see a church and put the directions in Google Maps, but found myself checking the app every twenty seconds to stay on track. I later realized I was missing out on looking around me and popping into random shops along the way. Being less accurate would’ve been better as long as I had a general sense of direction. Maybe it takes slightly longer to reach the goal state, but I explore more of $f$. The journey itself has value.
I think there are some interesting takeaways with this framing:
- Make your gradient computation less expensive. I tend to make few accurate steps and I think I can adjust the scale towards being less accurate and taking more steps. This is equivalent to an emphasis on “executing”
- Take bigger steps when in a rut. When things feel off, I find that doing something bigger to shake things up gets me out of the local minimum I might be in. For example, when I feel down, sometimes traveling to a new place or experiencing something new is a big enough step to make me feel better.
- Ask yourself how big is the decision you’re making. If the decision vector is small in magnitude, accuracy isn’t worth it (the inverse is also true)
- Be uncertain about things far from your current state. It’s easy to view people with more money, power, and fame as much happier, but I don’t think that’s true. Those folks are so far from $x$ in $V$ that our heuristics for these axes break down when we extrapolate that much.
- For example, I met someone who was a full-time paraglider instructor in Switzerland. I originally thought, “wow it’d be great to feel alive and see nature all the time”, but it’s so different from who I am right now that I can’t really evaluate what that’s like. Also, other people have different utility functions, so what works for them doesn’t necessarily work for you. Your heuristics for $f$ fall apart the further they are in $V$ relative to you.
- Remember that $f$ changes over time. This is different from gradient descent and adds more complexity. If you have some goal state and step towards it, maybe $f$ has changed by the time you get there.
- As a corollary, if you feel like you’re going in circles, this means that maybe that’s not a bad thing.
I spend a lot of time thinking and taking calculated executions. Maybe this isn’t the best for me—especially for steps that I know aren’t large in magnitude.
So I’m going to try executing more often and thinking less.
-
Gradient descent is the main algorithm for training models in machine learning. For a model with some chosen parameters, you know how “wrong”/”off” you are for some input. This error is the difference between the expected/correct output and what your model produces. Gradient descent looks at the space of parameters for the model and tries to adjust your parameters slightly in a way to reduce the error (improving the model’s performance). 3Blue1Brown has a great video with more of the details here. ↩
-
I feel like this sentence makes me sound like a LinkedIn influencer, but I promise that’s not what I’m going for 😅 ↩
-
This is actually gradient ascent, because we’re maximizing a utility function, rather than minimizing an error function. Same ideas hold. ↩
-
In gradient descent, there’s a constant $\alpha$ that tunes this. At the beginning of training your model, you generally make $\alpha$ larger, indicating you take big steps to explore the space and what areas are maximizing $f$ (this works because $f$ is continuous). Over time, you decrease $\alpha$ to take smaller steps, refining to the local region you’re at. ↩